Fetch As Google – From Googlebot’s Perspective
March 2, 2018
The Google Search Console Fetch and Render Tool is like putting on a pair of Googlebot goggles and looking at your own site through those lenses. If you have a simple website, (WordPress for example) that hasn’t been modified too much, you may not appreciate why this is important. But the more complex your site becomes with AJAX Javascript rendering or robots.txt rules, this tool becomes critical to understanding why your site is, or is not, optimized for crawling— and search in general.
When you ask Google to Fetch and Render a URL, Google makes a few requests to that URL, one to your robots.txt file, and one to your favicon. Some of these request matter more than others in terms of SEO signals. I set up some logging on a simple test site: rsvpz.co, to see if there was anything interesting going on, and hopefully to understand more about what these requests might signal about what Google and Googlebot care about in terms of crawling, rendering, and indexing.
The test pages were simple PHP pages with only a single line of content, “You’re invited!” The PHP was used to collect server variables and HTTP headers and send them to me as an email. This and server logs is how I gathered this information. Now let’s dive in!
Fetch and Render
The two side-by-side views of the page are generated from rendering the page with two different user agents that Google calls the Web Rendering Service (WRS).
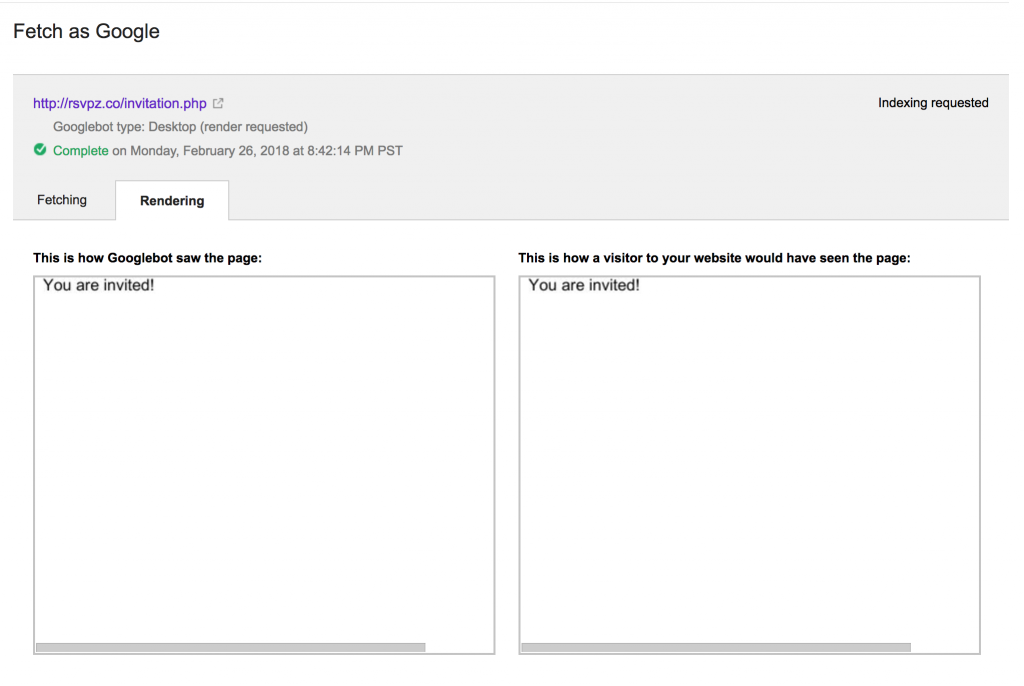
The rendering of the page under the heading, “This is how a visitor to your website would have seen the page” comes from the Google user agent:
Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko; Google Web Preview) Chrome/41.0.2272.118 Safari/537.36
As the user agent string suggests, this is essentially a Linux computer running a Chrome browser at version number 41. This is a little odd since that version was released in March of 2015. But this might be a good hint as to what technologies you can expect Googlebot to reliably recognize and support in discovering the content of your page.
Google sets some additional limits to what you should not expect for the WRS to render, namely: IndexedDB and WebSQL, Service Workers and WebGL. For more detail on what browser technologies are supported by Chrome 41, check out caniuse.com.
The rendering in the Fetching tab under the heading, “Downloaded HTTP response” and the Rendering tab under the heading, “This is how Googlebot saw the page” both come from the same request. The user agent is:
Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko; Google Search Console) Chrome/41.0.2272.118 Safari/537.36
The user agent string is practically the same as the Google Web Preview user agent. The user agent only differ in name.
The most significant difference between these two requests is that this request sets the Cache-Control header to ‘no-cache’ to ensure that the content at the URL is as fresh as possible. As the RFC states: “This allows an origin server to prevent caching even by caches that have been configured to return stale responses to client requests.” This makes sense; Google wants to have the freshest index possible. Their ideal index would never be even a second old.
This is further demonstrated in how Google makes requests when you request that a URL is indexed.
Requesting Indexing
Requesting indexing is a great tool when you have new pages on your site that are time sensitive, or your if site/pages go down due to server bugs. It is the fastest way let Googlebot know that everything is up and running. When you “Request Indexing” you are asking Googlebot to crawl the page. This is the only way to do this— submitting sitemaps an implicit request for Googlebot to crawl your pages, but this does not mean that all the URLs will be crawled.

When you click “Request Indexing,” Googlebot request you page not once, but twice. Unlike the previous requests, these requests are from “Googlebot” itself (Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)). This duplicate request may provide some insight into what Google thinks and cares about when crawling the internet.
The first request is similar to the requests mentioned above. The Cache-Control header is set to no-cache, ensuring that the requested resource is not stale. In my test case, the Accept-Language header was set to the default language of my Google Search Console account, even though I had not specified a default language in for the site. The server is also in the US so this makes sense.
Googlebot Request #1 HTTP Headers
| Name | Value |
|---|---|
| Accept-Encoding | gzip,deflate,br |
| User-Agent | Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html) |
| From | googlebot(at)googlebot.com |
| Accept | text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 |
| Connection | close |
| Cache-Control | no-cache |
| Accept-Language | en-US |
| Host | rsvpz.co |
Seconds later, the second request comes along with two important changes. First, the Cache-Control header is no longer set. This implies that the request will accept a cached resource.
Why does Googlebot care about caching? My belief is that it is to understand if and how the page is being cached. This is important because caching has a big effect on speed— cached pages do not need to be rendered on the server every time they are requests thus avoiding that time on the server wait time. A page that is cached, and how long it is cached is also a signal that the content may not be updated frequently. Google can take this as a sign that they do not need to crawl that as often as a page that changes every second in order to have the freshest version of the page. Think of this like the difference between this blog post and the homepage of Amazon or a stock ticker page.
Googlebot Request #2 HTTP Headers
| Name | Value |
|---|---|
| If-Modified-Since | Mon, 26 Feb 2018 18:13:14 GMT |
| Accept-Encoding | gzip,deflate,br |
| User-Agent | Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html) |
| From | googlebot(at)googlebot.com |
| Accept | text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 |
| Connection | close |
| Host | rsvpz.co |
The second request, as you might have guessed, does not set a Cache-Control header. This way, Google is able to “diff” the cached and non-cached version of the page to see if or how much they have changed.
The other change between the first and second request is that Googlebot does not set the Accept-Language header which allows the server to respond with the default language. This is likely used to understand if and how the page and site are internationalized.
Perhaps if I had set rel=”alternate” tags the crawl behavior would have been different. I will leave that experiment up to you.
I’ve spent a lot of time with Googlebot and SEO experiments lately. I am just starting to write about them. Sign up for email updates to learn more about Googlebot and leave a comment if you have any questions. Thanks for reading.