Intro to SQL User-Defined Functions: A Redshift UDF Tutorial
February 1, 2020
As a data analyst, your credibility is as valuable as your analytical skills. And to maintain your credibility, it’s important to be able to answer questions correctly and consistently. That’s why you must be careful to integrate reproducibility into your SQL analyses. This tutorial is going to show you how you can use Redshift User Defined Functions (UDFs) to do just that.
Reproducibility in SQL Analysis
I’ve learned that there are two broad factors to reproducibility. The first is the data—different data for the same analysis is going to produce different results. A good example would be a court case: if you ask two witnesses the same question, each one will probably tell you something similar but likely slightly different.
The second factor is the analytical methods. If we use the court case example again, this would be like the prosecution and the defense asking a witness the same question in two different ways. The lawyers would do this with the intent to get two different answers.
This post is more concerned with the second factor of reproducibility, the analytical method. Whenever you have to write complex SQL queries to get an answer, your analytical method (the SQL query) becomes a big variable. SQL is iterative by nature! Think about it, just be adding and removing “WHEN” conditions, you’re liable to drastically change your results.
As you iterate on a numerical calculation or classification in a CASE expression you are likely to change your query results. And what happens when you have to perform the same analysis weeks later? You better hope you use the same iteration of your SQL query the second time as the first!
And that is exactly where User-Defined Functions become so valuable!
User-Defined Functions (UDFs) are simply a way of saving one or more calculations or expressions with a name so that you can refer to it as a SQL function for further use.
What are User Defined Functions?
User-Defined Functions can be used just like any other function in SQL like SUBSTRING or ROUND except you get to define what the output of the function is, given the input.
User-Defined Functions (UDFs) are simply a way of saving one or more calculations or expressions with a name so that you can refer to it as a SQL function for further use.
They are a great way to simplify your SQL queries and make them more reproducible at the same time. You can basically take several lines of code that produce one value from your SELECT statement, give it a name, and keep it for future use. Using UDFs, you can ensure that, given the same data, your calculations will always produce the same result.
UDF Functions are Scalar Functions. What does scalar mean?
As you learn about UDFs, you’ll see references to the word “scalar.” Scalar just means that the function is defined with one or more parameters and returns a single result. Just like the ROUND function has one parameter (the number) and an optional second parameter (the number of decimal places for rounding) and returns the rounded number. The function is applied to every value in a column, but it only returns one value for each row in that column.
A Hello World! SQL UDF Example
If you are familiar with any kind of programming language, this should be pretty simple. The CREATE FUNCTION syntax only requires a function name and a return data type. That’s it.
A function called hello_world that returns ‘HELLO WORLD!’ every time would look like this:
create function hello_world ( ) returns varchar stable as $$ select 'HELLO WORLD!' $$ language sql;
In that case, the input data type and the output data type are both varchar because “HELLO WORLD!” is a text output. You could use your function like this:
select hello_world() as my_first_function;
And you’d get an output that looks like this:
my_first_function HELLO WORLD!
But that wouldn’t be very interesting. You’ll generally want to modify the input(s) of your functions. Let’s take apart a more interesting UDF example.
How to Write SQL UDF Functions
This example function, called url_category takes a varchar as an input (a URL) and returns a varchar output (the category of the URL). To do this, the function compares the input (shown as $1 because it is the first parameter) to the conditions of a case expression.
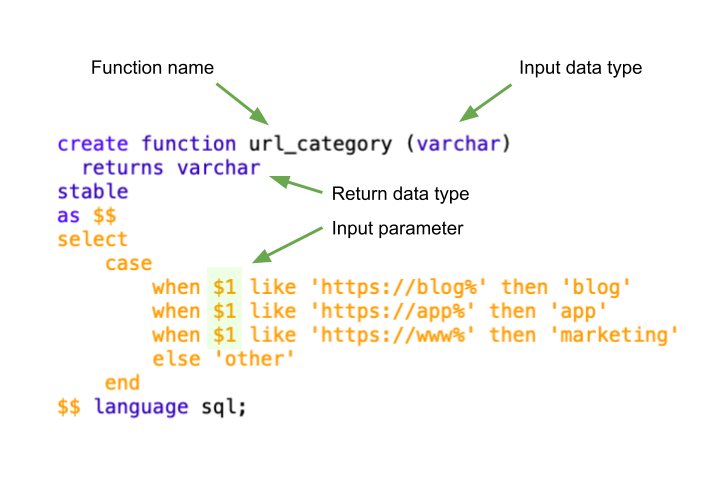
You could also write this function with two parameters. Here’s an example if you were using Google Analytics data. You could take in the parameters, hostname and a page_path to get more granular with your URL categorization.
SQL UDF Functions with Multiple Arguments
This is Redshift’s example from their docs. It takes two parameters (both specified as float) and returns the value that is greater of the two.
create function f_sql_greater (float, float) returns float stable as $$ select case when $1 > $2 then $1 else $2 end $$ language sql;
To refer to the different parameters in the function, you just use the dollar sign ($) and the order of the parameter in the function definition. As long as you follow that convention, you could go wild with your input parameters!
Redshift UDF Limitations
UDFs are basically restricted to anything that you can normally do inside a SELECT clause. The only exception would be subqueries—you cannot use subqueries in a UDF. This means you’re limited to constant or literal values, compound expressions, comparison conditions, CASE expressions, and any other scalar function. But that’s quite a lot!
Common UDF Errors and their Causes
Once you start writing UDFs, you’ll find that it’s pretty easy going but there are two especially common “gotchas”
ERROR: return type mismatch in function declared to return {data type}
DETAIL: Actual return type is {data type}.
This just means that you’ve created a function where the output value has a different data type than you said it would. Check that the return data type that you specified is the same as the function is actually returning. This can be tricky if your function is using a CASE expression because a CASE could accidentally return two different data types.
ERROR: The select expression can not have subqueries.
CONTEXT: Create SQL function “try_this” body
This means you tried to write a SELECT statement in your function that includes a subquery. You can’t do that.
ERROR: function function_name({data type}) does not exist
HINT: No function matches the given name and argument types. You may need to add explicit type casts.
There is one especially odd thing about Redshift UDFs. You can have several functions with the same name as long as they take different arguments or argument types. This can get confusing. The error here means that you’ve called a function with the wrong type of argument. Check the input data type of your function and make sure it’s the same as you input data.
Scaling your SQL Analysis with Confidence!
User-Defined Functions make it really easy to repeat your analytical method across team members and across time. All you have to do is define a function once and let everyone know that they can use it. On top of that, if you want to change the logic of your function you only have to do it in one place and then that logic will be changed for each user in every workbench, notebook, or dashboard!
Take advantage of this clever tool. Your team will thank you, and you will thank you later!