How does Dataform work? A primer on the ref function
October 5, 2023
You may have heard about Dataform or even be curious about using it. If so, you’re in the right place. My goal in this post is to introduce the tool and the interesting story and technology behind it. We’ll start with a brief history, then zoom through the context in which it arose, and finally get into the technical details of how it works.
Dataform is an analyst-friendly data transformation tool that makes it easy to manage ELT pipelines with just SQL. In other words, it removes much of the complex data engineering work of transforming messy tables into datasets that are prepared for analysis.
It started as an open-source SaaS in late 2018, described by its developers as “a framework for managing SQL-based data operations in BigQuery, Snowflake, and Redshift.” In 2020, the startup was acquired by Google and now, after years of years of relative silence, it has become generally available as part of the BigQuery ecosystem.
Now that Dataform has its own spot in the BigQuery sidebar navigation, it’s time to get familiar with it. And, especially if you are a cost-conscious data organization, it might be time to consider using it.
But before we dive in, I want to bring you up to speed on the last ten years of progress that gave rise to Dataform. This is my 200-word summary of the “modern data warehouse.”
Briefly: ETL, DAGs, Orchestration
Dataform is part of a big trend in data warehousing known as ELT. ELT stands for Extract, Load, Transform, and it differs from traditional ETL because, instead of data being loaded into a database/data warehouse in a form ready for analysis, the data is loaded in a less refined form. Then, the transformation takes place using successive SQL transformations—filtering, typecasting, and combining data until it is prepared for analysis.
Dataform and the popular dbt framework both employ DAGs (directed acyclical graphs), also known as dependency trees, to organize and orchestrate successive transformations. DAGs ensure that each transformation can only occur after “upstream” transformations have occurred that a transformation depends on.
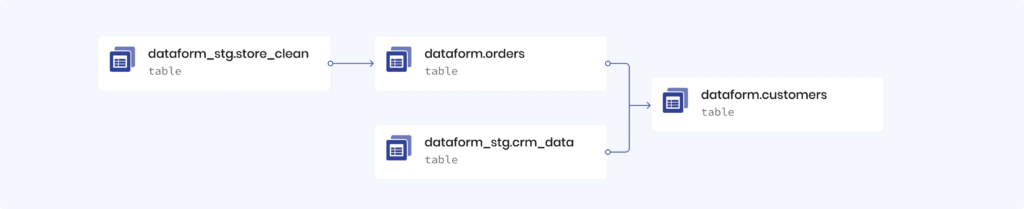
The image above shows a DAG. You can follow the data transformation from left to right. Two tables (top left and bottom right) are transformed and combined to create dataform.customers, a table of customers that is prepared for analysis.
If you were to create the customers table without Dataform in (plain SQL); you’d have to have to execute two DDL statements consecutively:
CREATE TABLE dataform.orders AS (SELECT ... FROM dataform_stg.store_clean WHERE ...)CREATE TABLE dataform.customers AS (SELECT ... FROM `dataform_stg.store_clean JOIN dataform_stg.crm_data JOIN dataform.orders ON ... GROUP BY ...)`
That doesn’t seem hard because it’s just two statements, but this becomes a lot harder to orchestrate as you get more and more interdependent tables.
Let’s take a look at how simple this is in Dataform. Notice how the only code that you have to write (and the only thing you have to worry about) is the SQL queries that define each table.
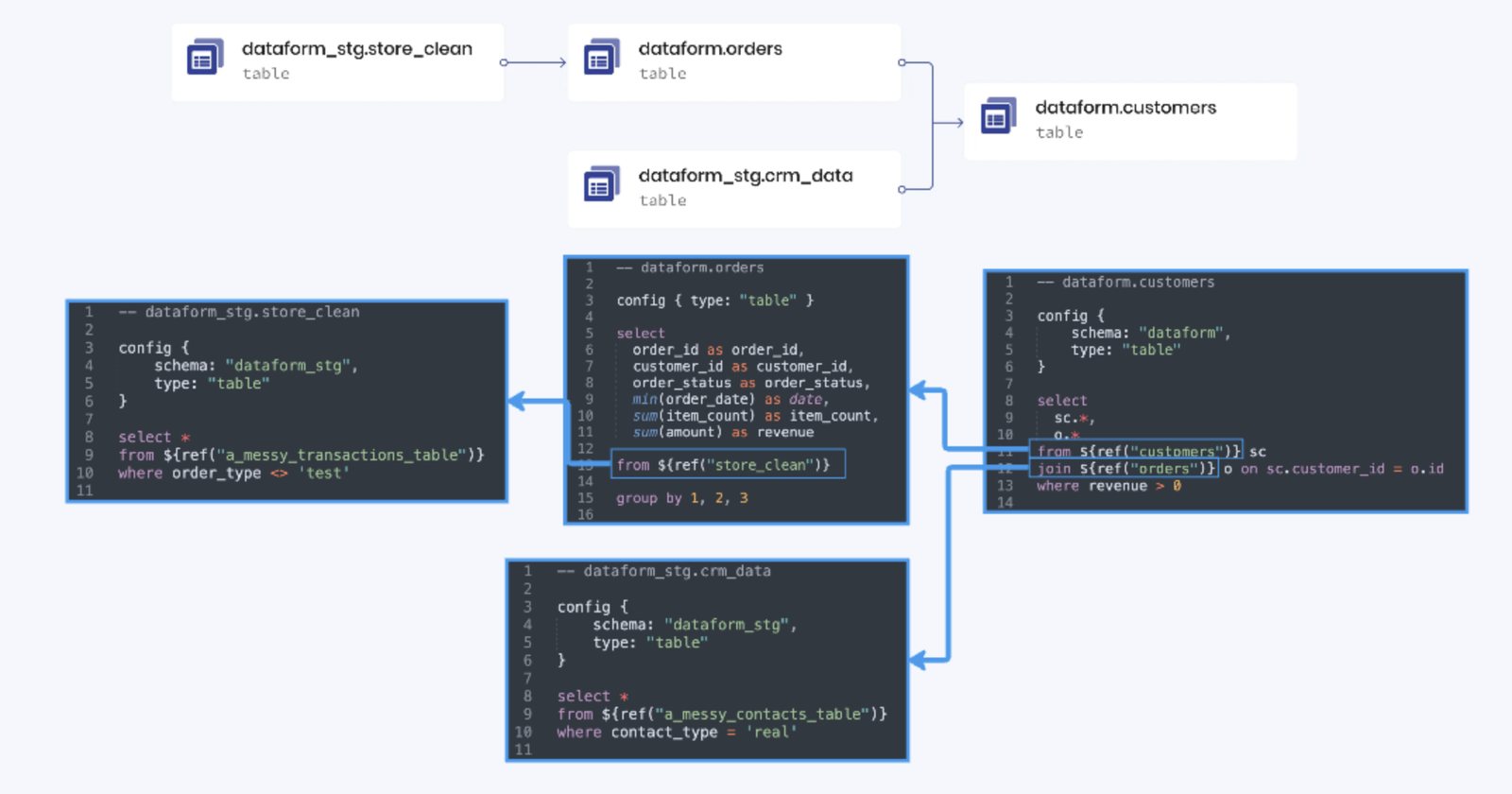
The orchestration that runs behind the scenes is the true magic of Dataform. And the glue behind all of it is the ref() function. Everything else is just sugar on top.
What does the ref function do in Dataform?
The ref function gets its name by shortening the word “reference.” As you can tell from the image above, it’s used in SQLX code to reference another table or view without writing out the fully qualified table name directly in the code. Referencing tables is just part of what the function does.
If you look at the source code, the ref() function does two things: 1) it appends the referenced table to the list of the current definition’s dependencies, and 2) it resolves (writes out) the fully qualified table name, for example: dataform.orders.
So what?
Simply put, the ref() function tells Dataform that there is a dependency from one definition to another. Then, whenever you save a file, Dataform has all the information it needs to compile a dependency tree. The dependency tree then allows Dataform to do a few things:
- Draw compiled graphs: In the Compiled Graph tab in Dataform, you’ll see a visualization of the dependency tree.
- Check for circular dependencies among tables, which Dataform won’t allow because it would cause an infinite loop.
- Execute the DDL statements that create the tables and views in the right order.
A dependency tree example
To illustrate that point, here’s a compiled graph visualization from Dataform.
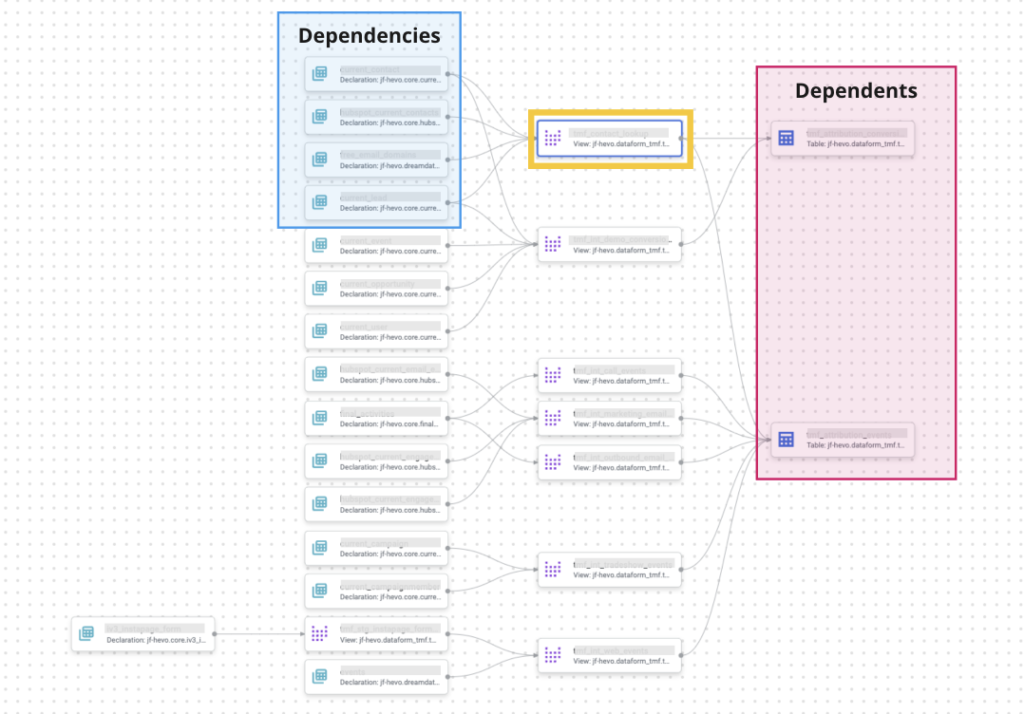
Let’s focus on the gold view node. There are sets of tables on either side: Dependencies on the left and Dependents on the right. Dataform must execute all the definitions in the Dependencies before the view can be defined. Similarly, the view must be defined before all the Dependents can be defined. If this ordering weren’t enforced, BigQuery would light up with errors about tables that don’t exist or columns of the wrong type.
The next image shows the Executions tab in Dataform. As you can see, the view definition is executed well before the two Dependents definitions.
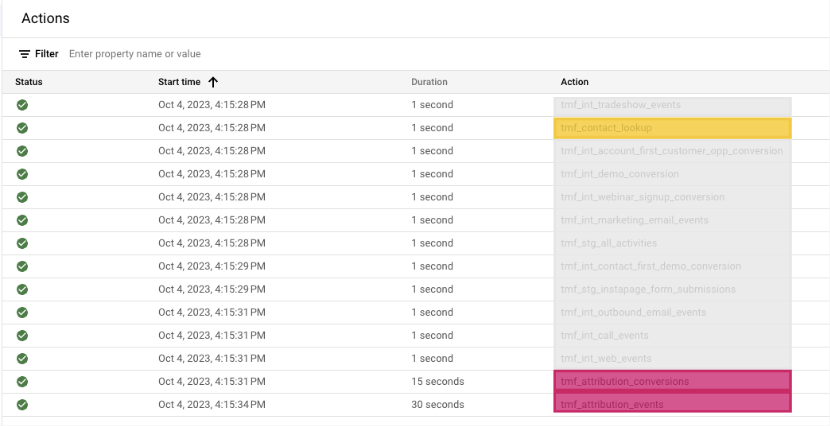
It’s also worth noting that the tables listed as Dependencies in the graphic above are all source declarations. So, while they are technically dependencies, they won’t be listed in the execution because there is no DDL to execute. (They must exist for the Execution to run, though.)
That’s it! That’s fundamentally how Dataform works. As I said before, there is a lot of other great functionality on top of orchestrating the execution of a dependency tree that makes Dataform a production-grade data transformation tool. I’ll mention its Git integration, testing capabilities, and integration with the broader GCP ecosystem, to name a few. But once you understand the core functionality, you’ve got what you need to get started.
A few more thoughts on the ref function
One thing that’s easy to overlook about ref‘ing dependency tables and views is that the definition of the table or view that you’re referencing may change. For example, they may join in or union on a new table. The beauty of the automatically generated dependency tree is that Dataform will discover the relationship between dependencies and dependents and add the new upstream tables to the current tables list of dependencies—no need to even think about it.
Having used both dbt and Dataform, I have to say there is one thing missing about Dataform refs: aliasing. The nice thing about dbt is that you can use any name you like for your tables. In contrast, Dataform tables must match the table’s name in the database. That functionality makes it much easier to swap out whole portions of DAGs. You just have to change the aliased names of the tables in their definitions. Doing that in Dataform requires either changing table definitions or the arguments in every call to the ref function that needs to be changed. </rant>
Have questions about Dataform functionality? Let me know in the comments, or send me a connection on Linked.