I’ve had a few SEO consulting projects lately that have given me a chance to work with many more keywords than anybody should be working within a spreadsheet. When I come across these types of projects, I use the same workflow: bring all the data into a database and run the analyses in SQL.
I find it immensely satisfying to work with SQL for a couple of reasons: 1) it gives me a sense of validation for all the time I spent learning SQL, and 2) it’s just a better, more scalable, less error-prone way to do analytics.
Now, with the timing of Google’s announcement that Google Search Console data be ingested into Google BigQuery, I figured it would be a great time to share some tips and tricks that I’ve picked up across Postmates, Panoply, Census, and a number of different projects.
This post is a beginner’s intro to SEO analytics in SQL. It should help just about anyone start running SQL queries to provide meaningful answers about their keyword data. It’s not going to show the most interesting stuff—I’ll save that for another post. 🙂
Let’s get the setup out of the way so we can get to the analytics!

Step 1. Setup your SQL database
I like to use Postgres for this stuff because it’s easy to set up and can run on my laptop, and because I can run it on my laptop, it’s completely free. That does, of course, limit the size of the data that I can work with, but the fact is, it’s over 100x the amount of data I could work within a spreadsheet. And that’s not too bad!
Surprise! The first step of this tutorial actually isn’t on this tutorial. It’s on my previous tutorial about setting up Postgres on Mac. Head over there and get Postgres running on your local machine (aka computer.)

Once you’ve got Postgres up and running, you’ll need to create a table in your database that will hold your keyword data.
Step 2: Create your table(s)
If you’ve ever used SQL, you know that all the data you want to analyze must be stored in a table (or tables). Database tables, just like the one shown in the image above, are made up of columns and rows.
A row, sometimes called a record, represents a single instance of the data being stored in the table. In this case, each row will represent a URL’s ranking for a specific keyword and contain the corresponding data about that ranking.
A column, sometimes referred to as a field, represents a specific attribute or piece of information about the data being stored in the table. In this case, I’m using data from SEMRush, so the table will have the following columns:
| Word | Definition |
| Keyword | The search term |
| Position | The percentage of overall site traffic to the URL comes from a given Keyword to a page. |
| Previous position | The ranking of a page on a search engine results page (SERP) for a given Keyword in the previous month. |
| Search volume | The estimated number of times a particular keyword is searched for on Google |
| Keyword difficulty | A score or measure of how difficult it is to rank a page in Google search results page for the Keyword |
| CPC | Cost per click on Google Ads |
| URL | Uniform Resource Locator, the address of the page |
| Traffic | Estimated volume of traffic to the URL for the corresponding Keyword |
| Traffic (%) | The percentage of overall site traffic to the URL that comes from a given Keyword to a given page. |
| Traffic cost | The estimated cost of driving the same amount of traffic to a page through Google Ads |
| Competition | The level of competition among advertisers or publishers for a particular keyword |
| Number of results | The total number of search engine results that contain a particular keyword |
| Trends | Patterns or changes over time in search volume, keyword difficulty, or other metrics related to the keyword |
| Timestamp | A record of the date and time when the ranking was recorded |
| SERP features by keyword | Special elements or features that appear in search engine result pages for a particular keyword, such as featured snippets or video results. |
| Keyword intents | The underlying motivations or goals of users searching for a particular keyword or set of keywords, such as informational, transactional, or navigational. |
At this point, you might be wondering, “if you’re just working with a 10k line CSV, why use SQL instead of a spreadsheet?”
The short answer is I’m going to get lots of these files and put them all in the same table. For example, if I want to examine the overlaps between multiple sites, then I’ll need at least two of these files. And on top of that, some things are easy to do in SQL that are just about impossible to do in a spreadsheet.
Let’s leave that discussion behind and move on.
To store all this data in a table, you first have to define the table. The table creation syntax requires two things: the name of each column and the data type of each column. For a SEMRush export, the table creation syntax looks like this. The table’s name is “positions.”
💡Notice each column name is listed immediately, followed by the data type of that column.
💡 Notice that the column names are “snake cased” (lowered cased with underscores instead of spaces) because, in Postgres, all column names default to lowercase, and spaces don’t work.
CREATE TABLE positions (
keyword character varying,
position numeric,
previous_position numeric,
search_volume numeric,
keyword_difficulty numeric,
cpc numeric,
url character varying,
traffic numeric,
traffic_pct numeric,
traffic_cost numeric,
competition numeric,
number_of_results numeric,
trends character varying,
timestamp timestamp without time zone,
serp_features_by_keyword character varying,
keyword_intents character varying,
domain character varying
);If you’re familiar with databases, you’ll probably notice that I’m pretty lenient in defining data types for these columns. Why? Well, partly because I’m lazy and partly because I didn’t want to be too specific and realize that I couldn’t import the data because a string was too long or something.
If this were a production database, I’d want to be a lot more specific about the types because it affects database performance, joins between tables, and storage requirements. Here’s more on why you would care about that in production. But this is just for analysis, and I’m not worried if these queries take an extra fraction of a second to run.
To create the table, you’d run the command in Postico just as you would a SELECT query.

Once you run the command, an empty table will be created, ready to be populated with data.
Step 3: Import your SEO data
For this step, it’s good to refer back to the previous Postgres tutorial, but for the most part, it’s easy. You’ll need to do two things:
- Edit your CSV file so that the column names in the header row are snake-cased and match the columns of your table. (Technically, this is optional since you’re defining the table’s columns in the same order as the CSV exports, and Postico is fine with that, but it’s a good practice anyway.)
- Upload your CSV to Postgres using Postico’s CSV upload feature.
To upload the SEMRush CSV file, you’ll choose commas as the Separator and leave the rest of the settings in their default setting. If you use data from a different source, you might find that you have to change these settings, though. Finally, choose “Match Columns by Order” so you don’t have to manually select each column.

Once you’re done with that, your table is ready for some lightning-fast SQL analytics.
Step 4: Get to know the data
The first thing I do when I see a new table of data is run a few queries to understand the nature of the data—not to analyze it—just to get familiar with it.
For this example, I used keyword ranking data for a couple of big sites: www.meta.com and about.meta.com. It’s a good demo data set because there is a wide range of keyword search volumes.
Let’s try a few of these queries!
What are the highest search volume keywords?
There are a couple of interesting things about the top searched keywords for a site: 1) they often provide a general overview of the topics for a site, and 2) they may represent ample opportunities for optimization. Let’s look at the top 100 keywords by volume.
select *
from positions p
order by p.search_volume desc💡Notice that I’ve “aliased” the table called “positions” with the letter “p.” That’s so I can refer to the table in other parts of the query (i.e., p.search_volume) without writing “positions” each time. I could skip aliasing and referencing the table name in this query because there is only one table in the query, but it’s a good practice when it comes to joins.

To no one’s surprise, “facebook” is the top searched keyword with 124 million monthly searches! That’s followed by the names of the rest of Meta’s major apps and products.
As expected, this query highlighted the site’s main topics (even if they don’t rank in the top 3 for all of them).
What’s the distribution of search volume for these keywords?
Let’s group the keywords by their order of magnitude with log base 10.
select ceiling(log(10, p.search_volume)),
count(*)
from positions p
group by 1
order by 1💡Notice that in the group by and order by clauses, I used the alias “1” to refer to the first field in the select statement, ceiling(log(10, p.search_volume) instead of rewriting the equation over and over.

Using the ceiling function with the log function, we can group keywords that are under 100, between 100 and 1000, between 1000 and 10,000, etc. In other words, the groupings tell you how many 0s are behind the search volume if you rounded them all up.
You can still see “facebook” represented twice in the 100M to 1B group. In this case, it’s not helpful to have duplicates when we’re trying to get a sense of the site’s keywords (not each page’s keywords).
I’ll challenge you to figure out how you might get rid of duplicate rows of the same keywords for the site. (There’s a hint in the next query.)
Step 5: Real SEO analytics in SQL!
Let’s move into the more actionable analyses. As we discovered in the last step, there is evidence that there are more than one URL ranking for some of the keywords. This might be an SEO issue, so we’ll have to get into some actual analysis. Let’s see how many keywords have multiple URLs ranking for them.
How many keywords have more than one URL ranking for them? (cannibalization risks)
Cannibalization in SEO is a common problem, especially for really large sites. When two or more pages compete to rank for the same keyword, you risk a lesser-value page outranking the greater-value page or having indexing problems.
This query finds all the keywords that have more than one URL from the domain that ranks for them and rolls up some metrics associated with the keyword. The metrics are, in order, the monthly search volume for the keyword and the number of URLs on the site that are ranking for it. The minimum and maximum rankings of these URLs and the list of all the URLs that are listed for the keyword.
select p.keyword,
max(p.search_volume),
count(distinct p.url),
min(p.position),
max(p.position),
string_agg(p.url, ', ')
from positions p
group by 1
having count(distinct p.url) > 1
order by 2 desc💡Notice the “having” clause. This clause filters the rows that have already been aggregated by the “group by” clause. In this case, we only want keywords with >1 URL ranking for them.

It looks like a few keywords have more than one page ranking in the top ten. That would be cause for investigation. In this case, the next step I would take would be to get more information by looking at the actual search page.
The interesting thing about many of these keywords is that they have high volume and multiple pages ranking for them because they are all brands and products of Meta. In other words, they are all “things.”
Recognizing these keywords as searches about “things,” rather than questions makes me think about Google’s Knowledge Graph. For the last piece of this analysis, let’s see if we can learn some more about how the entities (“things”) on this site fit in the Knowledge Graph.
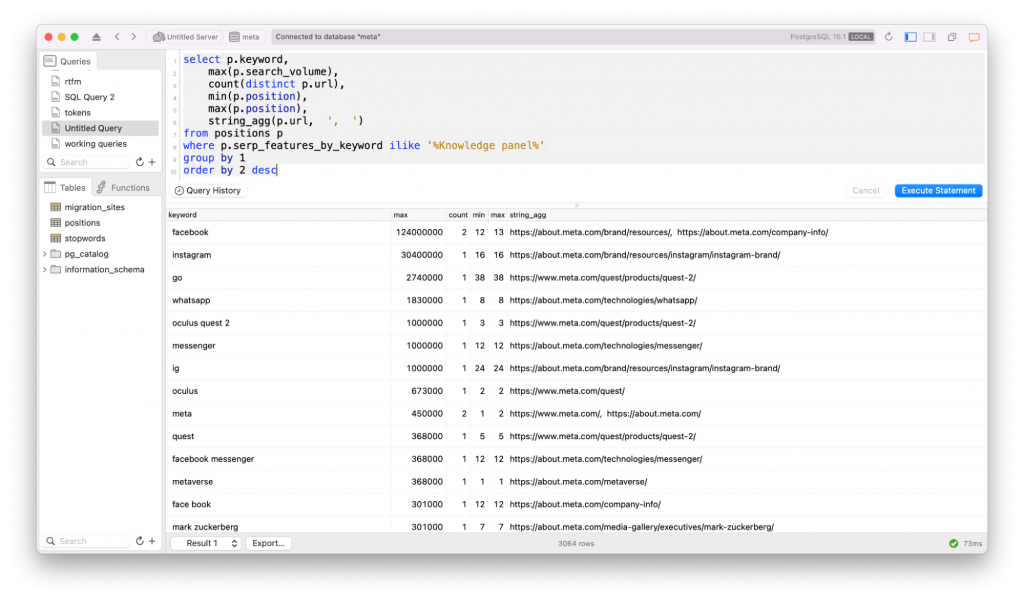
What Knowledge Graph Entities are represented on this website?
The answer to this requires a similar query, except we want to only look at keywords that have a “Knowledge Panel” SERP feature, and we want all of them (instead of just the ones with multiple URLs).
The metrics are all the same, but we see that, when we filter in keywords with corresponding Knowledge panels, how many “entities” are strongly associated with this site. And, of course, it confirms what we saw in the last query.
select p.keyword,
max(p.search_volume),
count(distinct p.url),
min(p.position),
max(p.position),
string_agg(p.url, ', ')
from positions p
where p.serp_features_by_keyword ilike '%Knowledge panel%'
group by 1
order by 2 desc💡Notice the order of operations in this query. The filtering happens before the grouping because it’s in the where clause, unlike the previous query’s having clause.

To nobody’s surprise, the main entities associated with Meta are Facebook, Instagram, WhatsApp, Messenger, Oculus, the Metaverse, and of course, that robot named Mark.
Why do entities matter in SEO? It relates to the cannibalization discussion earlier. When you are intentional about the entities that you want to target on your website, you can design an information architecture and linking strategy to signal which pages should be the “canonical” page for each entity. This is not only a good way to improve your rankings for the right pages when done right, but it also provides a great user experience.
Step 6: To infinity and beyond! ⚡
Hopefully, at this point, I’ve convinced you that SQL can answer just about any question that you come across in your SEO research or analysis. And more importantly, the answers are only limited by your ability to articulate the question and translate it into SQL!
There are a lot of ways you could build on this analysis. For example, you could crawl the site and import that data into a new table. Then, make comparisons between link quantity and anchor text and ranking. Or you could bring in competitor data. On and on it goes, depending on the problem you’re trying to solve or the opportunity you are trying to capture.
Do you have any other analyses that you think would be interesting?
Please leave them in the comments. I might write another one of these, so it would be great to see what I should write about.
If you need this type of analytics done on your site, feel free to say hi. 👋
Follow on LinkedIn
Pingback: Google Search Console Bulk Export for BigQuery: The Complete Guide • Trevor Fox