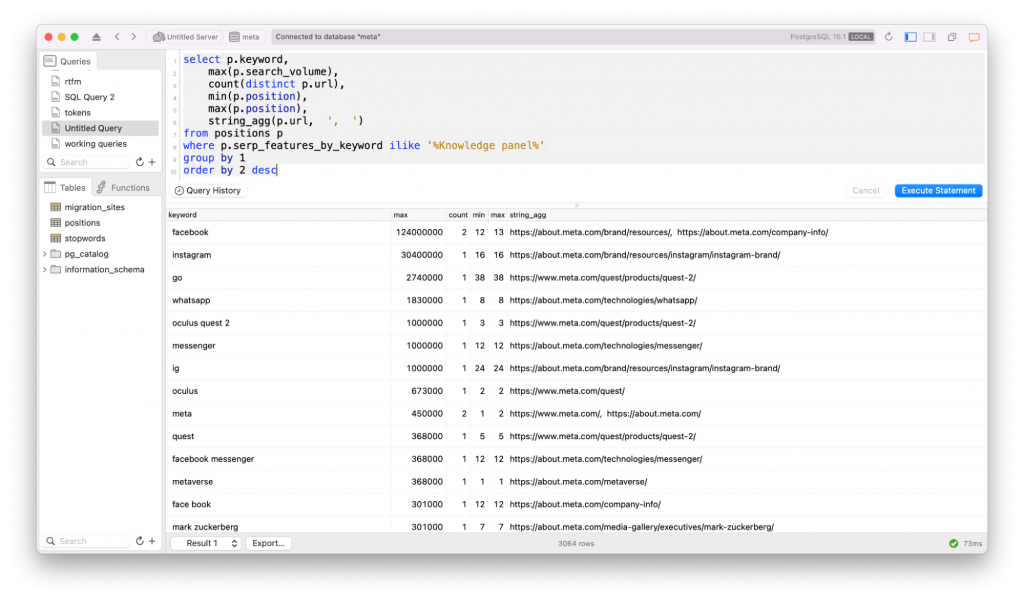
SEO SQL Pattern #1: Aggregating Position Metrics and CTR Curves
Google Search Console only provides a few metrics: impressions, clicks, CTR, and average position. The first three are easy to understand, but the average position can trip up even the savviest analyst if they’re not careful. That’s why I started this series on SQL Patterns for SEO with a (perhaps overly) thorough explanation of how […]
SEO SQL Pattern #1: Aggregating Position Metrics and CTR Curves Read More »