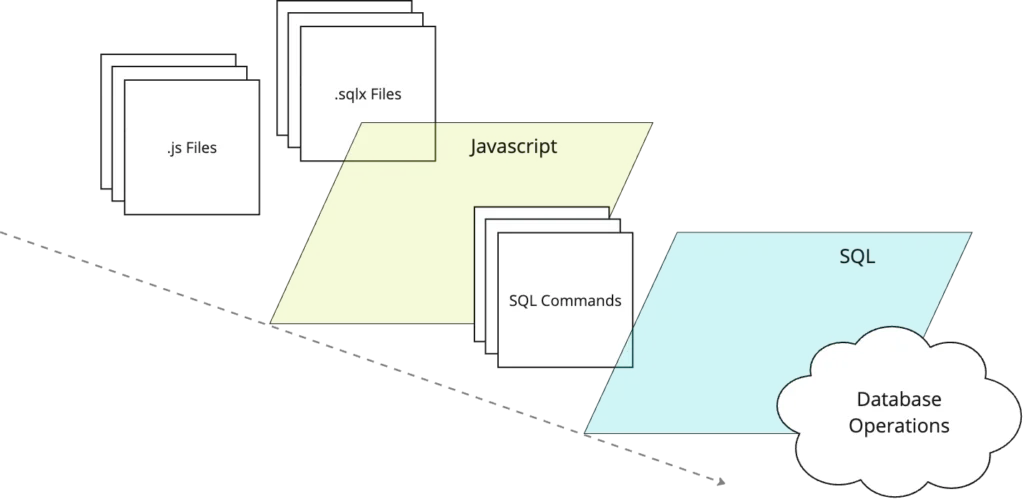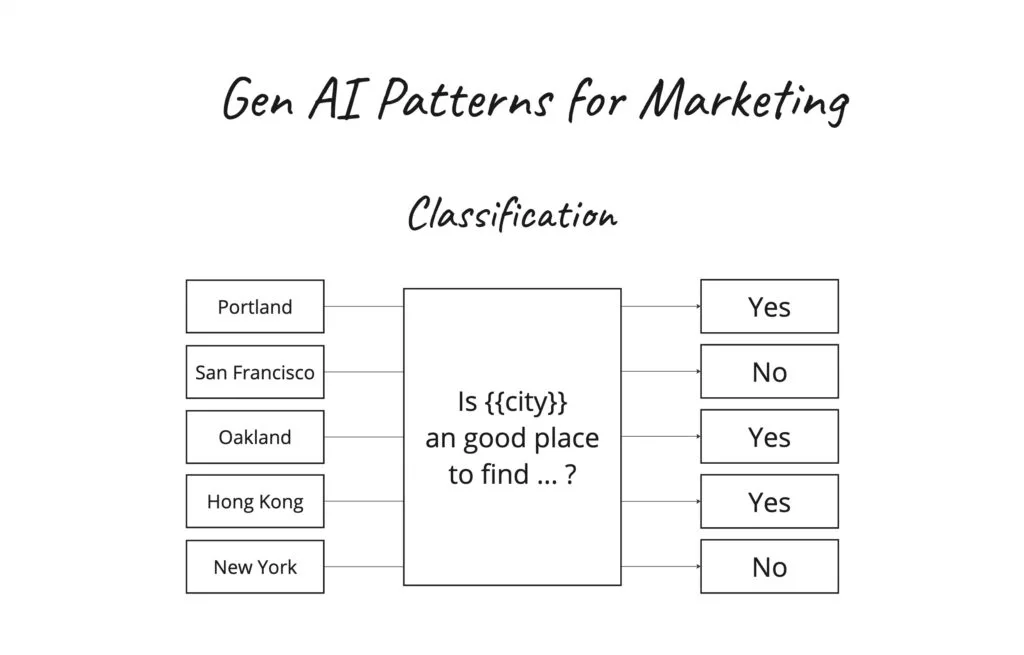
Using ChatGPT in Google Sheets for Classification (custom function included)
Classification is the generative AI-based pattern I use most frequently. Why? Three reasons: It’s perfect for tackling big tasks where 80% accuracy on 100% of cases is better than 100% accuracy on just 20%. This week alone, I’ve used classification to: Since Google Sheets is one of my go-to tools for small/quick data problems, I […]
Using ChatGPT in Google Sheets for Classification (custom function included) Read More »