Understanding SQLX and Javascript in Dataform
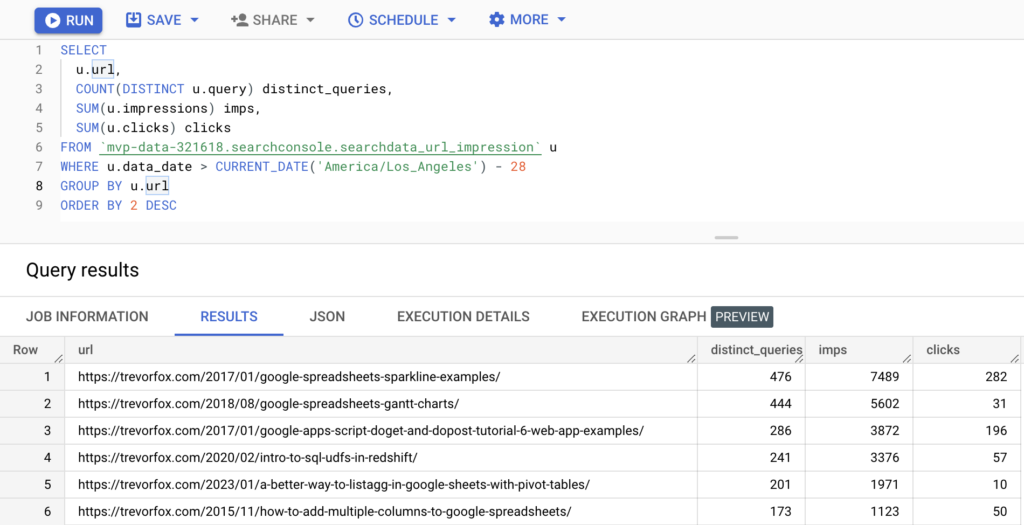
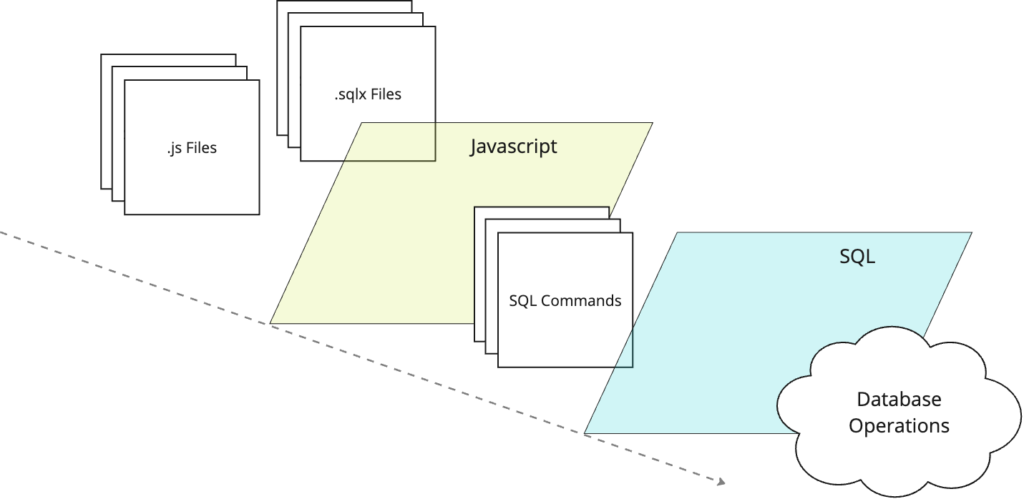
When you think of “programming languages for data,” Javascript probably doesn’t even make the list. Yet, if you’re using Dataform, it’s almost impossible to avoid. As you’ll learn in this article, Dataform is Javascript all the way down. Even SQLX files that you write are pretty much just Javascript files under the covers. So shed …