A Primer on Google Search Console Tables in BigQuery
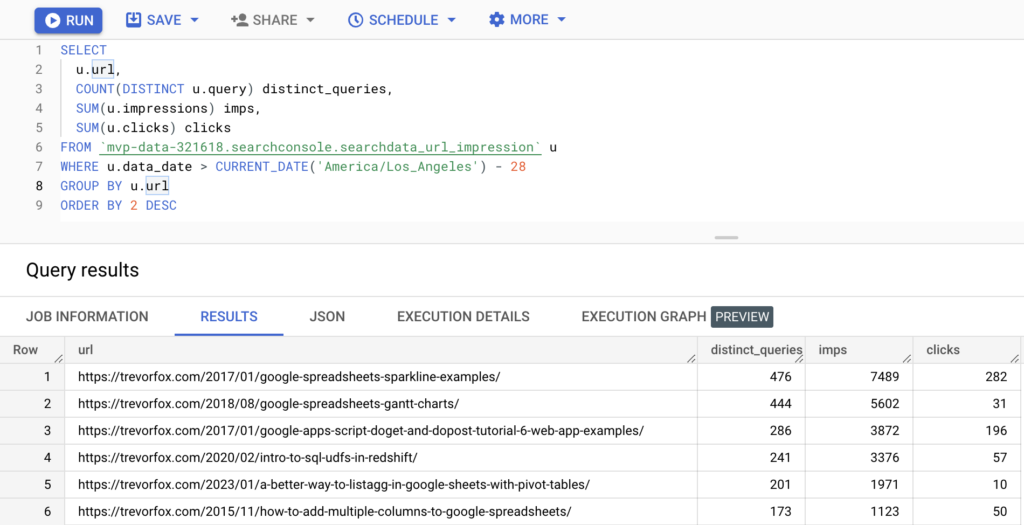
Discover the differences between the searchdata_url_impression and searchdata_site_impression tables, and learn how they can help you analyze your site’s performance at different levels of granularity.